Charles Bouillaguet set up a nice shiny website for libFES the library for exhaustive search on polynomial systems over 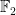
He calls his benchmarketing “bragging rights” … and boy has he earned those rights! Check it out, libFES is fast!
a blog about cryptography, math software and kittens
Charles Bouillaguet set up a nice shiny website for libFES the library for exhaustive search on polynomial systems over
He calls his benchmarketing “bragging rights” … and boy has he earned those rights! Check it out, libFES is fast!
Fayssal’s code which implements the Faugère-Lachartre approach to linear algebra for Gröbner bases is available on Github now. Fayssal did a Master’s project on linear algebra for Gröbner bases in the team of Jean-Charles Faugère.
Two days ago I wrote about LELA’s implementation of Gaussian elimination for Gröbner basis computations over
The Efficient Linear Algebra for Gröbner Basis Computations workshop in Kaiserslautern two weeks ago was a welcome opportunity to finally test out LELA, a library specifically written for linear algebra for Gröbner basis computations including for GF(2). The library implements the “Faugère-Lachartre” algorithm (a similar trick, though less developed, appeared before in PolyBoRi) and uses M4RI for dense parts over GF(2).
So, I ran my benchmark matrices through LELA, discovered a bug in the process, then Bradford returned the favour and discovered a bug in M4RI … Finally, below are the timings. The column PLE is the PLE algorithm as implemented in M4RI, M4RI is the M4RI algorithm as implemented in M4RI, GB is a very naive variant of the algorithm LELA uses and LELA is, well, LELA.
| problem | m | n | density | PLE | M4RI | GB | LELA |
| HFE 25 | 12307 | 13508 | 0.076 | 1.0 | 0.5 | 0.8 | 0.56 |
| HFE 30 | 19907 | 29323 | 0.067 | 4.7 | 2.7 | 4.7 | 3.42 |
| HFE 35 | 29969 | 55800 | 0.059 | 19.3 | 9.2 | 19.5 | 13.92 |
| Mutant | 26075 | 26407 | 0.184 | 5.7 | 3.9 | 2.1 | 12.07 |
| n=24, m=26 | 37587 | 38483 | 0.038 | 20.6 | 21.0 | 19.3 | 7.72 |
| n=24, m=26 | 37576 | 32288 | 0.040 | 18.6 | 28.4 | 17.0 | 4.09 |
| SR(2,2,2,4) c | 5640 | 14297 | 0.003 | 0.4 | 0.2 | 0.1 | 0.40 |
| SR(2,2,2,4) c | 13665 | 17394 | 0.013 | 2.1 | 3.0 | 2.0 | 1.78 |
| SR(2,2,2,4) c | 11606 | 16282 | 0.035 | 1.9 | 4.4 | 1.5 | 0.81 |
| SR(2,2,2,4) | 13067 | 17511 | 0.008 | 1.9 | 2.0 | 1.3 | 1.45 |
| SR(2,2,2,4) | 12058 | 16662 | 0.015 | 1.5 | 1.9 | 1.6 | 1.01 |
| SR(2,2,2,4) | 115834 | 118589 | 0.003 | 528.2 | 578.5 | 522.9 | 48.39 |
What this table means is that one can expect more than an order of magnitude of speed-up when using LELA – which is dedicated to these computations – instead of M4RI – which does not have the specialised algorithm implemented yet. For very small matrices sometimes M4RI/PLE win, but then not by a large margin. The only row where LELA doesn’t do so good is Mutant, which – btw. – is not an F4 matrix but comes from the MXL2 algorithm. It is possible that LELA’s sparse data structures are not that well equipped to deal with this rather dense matrix.
I am in the process of implementing the algorithm LELA uses in M4RI and will report updated timings here.
As you may know, today is the last day of the wokshop on Efficient Linear Algebra for Gröbner Basis Computations that Christian Eder, Burcin Eröcal, Alexander Dreyer and I organised.
I have to say that I am quite pleased with how the workshop played out. We planned the whole thing to be hands on: people were strongly encouraged to work on projects, i.e., to write code preferably together, in addition to attending talks. Those who attended a Sage Days workshop in the past, will know what workshop format I am referring to. Continue reading “Report: Workshop on Efficient Linear Algebra for Gröbner Basis Computations”
Now, that we have a decent PNG reader/writer in M4RI, it’s much easier to get some challenge matrices out of the library. Below, I list and link a few such matrices as they appear during Gröbner basis computations.
| file | matrix dimensions | density | PLE | M4RI | GB |
| HFE 25 matrix 5 (5.1M) | 12307 x 13508 | 0.07600 | 1.03 | 0.59 | 0.81 |
| HFE 30 matrix 5 (16M) | 19907 x 29323 | 0.06731 | 4.79 | 2.70 | 4.76 |
| HFE 35 matrix 5 (37M) | 29969 x 55800 | 0.05949 | 19.33 | 9.28 | 19.51 |
| Mutant matrix (39M) | 26075 x 26407 | 0.18497 | 5.71 | 3.98 | 2.10 |
| random n=24, m=26 matrix 3 (30M) | 37587 x 38483 | 0.03832 | 20.69 | 21.08 | 19.36 |
| random n=24_ m=26 matrix 4 (24M) | 37576 x 32288 | 0.04073 | 18.65 | 28.44 | 17.05 |
| SR(2,2,2,4) compressed, matrix 2 (328K) | 5640 x 14297 | 0.00333 | 0.40 | 0.29 | 0.18 |
| SR(2,2,2,4) compressed, matrix 4 (2.4M) | 13665 x 17394 | 0.01376 | 2.18 | 3.04 | 2.04 |
| SR(2,2,2,4) compressed, matrix 5 (2.8M) | 11606 x 16282 | 0.03532 | 1.94 | 4.46 | 1.59 |
| SR(2,2,2,4) matrix 6 (1.4M) | 13067 x 17511 | 0.00892 | 1.90 | 2.09 | 1.38 |
| SR(2,2,2,4) matrix 7 (1.7M) | 12058 x 16662 | 0.01536 | 1.53 | 1.93 | 1.66 |
| SR(2,2,2,4) matrix 9 (36M) | 115834 x 118589 | 0.00376 | 528.21 | 578.54 | 522.98 |
The first three rows are from GB computations for the hidden field equations cryptosystem (those matrices were provided by Michael Brickenstein). The “mutant” row is a matrix as it appears during a run of the MXL2 algorithm on a random system (I believe). It was contributed by Wael Said. The rows “random n=25,m=26” are matrices as they appear during a GB computation with PolyBoRi for a random system of equations in 24 variables and 26 equations. The remaining rows are matrices from PolyBoRi computations on small scale AES instances. Those rows which have “compressed” in their description correspond to systems where “linear variables” were eliminate before running the Gröbner basis algorithm.
The last three columns give running times (quite rough ones!) for computing an echelon form (not reduced) using (a) the M4RI algorithm, (b) PLE decomposition and (c) a first implementation of the TRSM for trivial pivots trick. As you can see, currently it’s not straight-forward to pick which strategy to use to eliminate matrices appearing during Gröbner basis computations: the best algorithm to pick varies between different problems and the differences can be dramatic.
This morning I delivered my talk titled “Algebraic Techniques in Cryptanlysis (of block ciphers with a bias towards Gröbner bases)” at the ECrypt PhD Summerschool here in Albena, Bulgaria. I covered:
Well, here are the slides, which perhaps spend too much time explaining F4.
PS: This is as good as any opportunity to point to the paper “Algebraic Techniques in Differential Cryptanalysis Revisited” by Meiqin Wang, Yue Sun, Nicky Mouha and Bart Preneel accepted at ACISP 2011. I don’t agree with every statement in the paper – which revisits techniques Carlos and I proposed in 2009 – but our FSE 2009 paper does deserve a good whipping, i.e., we were way too optimistic about our attack.
We finally (sorry for the delay!) finished our paper on the Mutant strategy. Here’s the abstract:
The computation of Gröbner bases remains one of the most powerful methods for tackling the Polynomial System Solving (PoSSo) problem. The most efficient known algorithms reduce the Gröbner basis computation to Gaussian eliminations on several matrices. However, several degrees of freedom are available to generate these matrices. It is well known that the particular strategies used can drastically affect the efficiency of the computations.
In this work we investigate a recently-proposed strategy, the so-called Mutant strategy, on which a new family of algorithms is based (MXL, MXL2 and MXL3). By studying and describing the algorithms based on Gröbner basis concepts, we demonstrate that the Mutant strategy can be understood to be equivalent to the classical Normal Selection strategy currently used in Gröbner basis algorithms. Furthermore, we show that the partial enlargement technique can be understood as a strategy for restricting the number of S-polynomials considered in an iteration of the F4 Gröbner basis algorithm, while the new termination criterion used in MXL3 does not lead to termination at a lower degree than the classical Gebauer-Möller installation of Buchberger’s criteria.
We claim that our results map all novel concepts from the MXL family of algorithms to their well-known Gröbner basis equivalents. Using previous results that had shown the relation between the original XL algorithm and F4, we conclude that the MXL family of algorithms can be fundamentally reduced to redundant variants of F4.
Despite being proven to be a redundant variant of the F4 algorithm, the XL algorithm still receives a lot of attention from the cryptographic community. This is partly because XL is considered to be conceptually much simpler than Gröbner basis algorithms. However, in doing so the wealth of theory available to understand algorithms for polynomial system solving is largely ignored.
The most recent and perhaps promising variant of the XL algorithm is the family of MXL algorithms which are based around the concept of Mutants. Assume in some iteration the XL algorithm finds elements of degree k while considering degree D > k. In a nutshell, the idea of the MutantXL algorithm is to continue the XL algorithm at the degree k+1 instead of D+1 which is what the XL algorithm would do. The natural question to ask is thus what Mutants are in terms of Gröbner basis theory; are they something new or are they a concept which is already known in the symbolic computing world under a different name?
I was in Darmstadt this week visiting the group which mainly drives the effort behind the MXL family of algorithms. As part of my visit I gave a talk about the relation of the Mutant strategy and the normal strategy used in Gröbner basis algorithms for selecting critical pairs called … the Normal Selection Strategy. In the talk we show that the Mutant strategy is a redundant variant of the Normal Selection Strategy. Also, I talked quite a bit about S-polynomials and how they can be used to account for every single reduction that happens in XL-style algorithms. Finally, I briefly touched on the “partial enlargement strategy” which was introduced with MXL2 showing that it is equivalent to selecting a subset of S-polynomials in each iteration of F4.
Unfortunately, there’s no full paper yet, so the presentation has to suffice for now.
Update: It was pointed out to me that a better way of phrasing the relationship is to state that the Mutant selection strategy can be understood as a redundant variant of the Normal selection strategy when used in F4. This way is better because our statement is strictly about an algorithmic relation and not about why did what first knowing what … which is how one could read the original phrasing.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}