There have been a few works recently that give FPLLL a hard time when considering parallelism on multicore systems. That is, they compare FPLLL’s single-core implementation against their multi-core implementations, which is fair enough. However, support for parallel enumeration has existed for a while in the form of fplll-extenum. Motivated by these works we merged that library into FPLLL itself a year ago. However, we didn’t document the multicore performance that this gives us. So here we go.
I ran
for t in 1 2 4 8; do ./compare.py -j $(expr 28 / $t) -t $t -s 512 -u 80 ./fplll/strategies/default.json done
where compare.py is from the strategizer and default.json is from a PR against FPLLL. Note that these strategies were not optimised for multicore performance. I ran this on a system with two Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz i.e. 28 cores. The resulting speed-ups are: 
As you can see, the speed-up is okay for two cores but diminishes as we throw more cores at the problem. I assume that this is partly due to block sizes being relatively small (for larger block sizes G6K – which scales rather well on multiple cores – will be faster). I also suspect that this is partly an artefact of not optimising for multiple cores, i.e. picking the trade-off between enumeration (multicore) and preprocessing (partly single-core due to LLL calls) right. If someone wants to step up and compute some strategies for multiple cores, that’d be neat.
 the unusually short vector in some lattice
the unusually short vector in some lattice  of dimension
of dimension  (say, derived from some LWE instance using Kannan’s embedding),
(say, derived from some LWE instance using Kannan’s embedding),  the block size used for the BKZ algorithm and
the block size used for the BKZ algorithm and 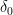 the root-Hermite factor for
the root-Hermite factor for 
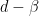 (Gram-Schmidt) vectors (denoted as
(Gram-Schmidt) vectors (denoted as 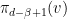 ) is shorter than the expectation for the
) is shorter than the expectation for the  -th Gram-Schmidt vector
-th Gram-Schmidt vector  under the GSA and thus would be found by the SVP oracle when called on the last block of size
under the GSA and thus would be found by the SVP oracle when called on the last block of size 

 v
v 