Both Sage and the Lmonade project were selected for Google’s Summer of Code 2015. If you are an eligible student, you should consider applying. If you need ideas what to work on, there are many fine projects/project ideas on either the Lmonade or the Sage GSoC pages. In particular, here are the fplll project ideas, for which I could be one of the two mentors.
Tag: flint
Improved Parameters and an Implementation of Graded Encoding Schemes from Ideal Lattices
Our paper (with Catalin Cocis, Fabien Laguillaumie and Adeline Langlois) on picking parameters and implementing GGHLite just hit eprint. Here’s the abstract:
We discuss how to set parameters for GGH-like graded encoding schemes approximating cryptographic multilinear maps from ideal lattices and propose a strategy which reduces parameter sizes for concrete instances. Secondly, we discuss a first software implementation of a graded encoding scheme based on GGHLite, an improved variant of Garg, Gentry and Halevi’s construction (GGH) due to Langlois, Stehlé and Steinfeld. Thirdly, we provide an implementation of non-interactive N-partite Diffie-Hellman key exchange. We discuss our implementation strategies and show that our implementation outperforms previous work.
Sage/FLINT Days aka Sage Days 35
I am writing this while waiting for my taxi to leave Sage Days 35. Although, I didn’t get much actual coding done, it was great fun and very useful. I met a lot of old friend, new faces and managed to put faces to e-mail addresses.
In terms of coding projects, first, I tried to speed up linear algebra mod p where p is a 32 or 64 bit prime. But it turns out that any trick I could think of could not improve on Frederik’s code. So that didn’t lead anywhere but I allowed me to read some code of FLINT2 (very readable) and admire how carefully it is written.
My other two projects both involved evaluate–pointwise-multiply–interpolate algorithms for fast matrix-matrix products over finite extension fields or for matrices with polynomial coefficients (over prime fields). After my talk on M4RI(E) David Harvey worked out how to improve multiplication over 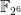
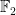
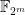

I also contributed a bit to #12177 which is about a “prime slice” implementation of matrices over 
Sage/FLINT Days in Warwick 17 – 22nd December 2011
“A Sage Days workshop around the theme of Algorithms in Number Theory and FLINT.”

See http://wiki.sagemath.org/SageFlintDays for more information and registration.
PS: I’ll be talking about M4RI(E) … big surprise.
