Fplll 4.0.4 was released in 2013. Fplll 5.0.0, whose development started in autumn 2014, came out today. About 600 commits by 13 contributors went into this release. Overall, fplll 5.0 is quite a significant improvement over the 4.x series.
Development model
Perhaps the most significant change is the change of development model. Previous versions of fplll, while open-source, were developed behind closed doors with tarballs being made available more or less regularly. Reporting a bug meant dropping Damien an e-mail.
Starting in autumn 2014, development is now coordinated publicly on GitHub. Developers send pull requests, reporting a bug means opening an issue, etc. Hence, development is more transparent and, most importantly, inviting. Additionally, for those who wish to get involved, we collect how-to information in our contributing guidelines. There is now also a public mailing list for all things fplll development and the occasional joint coding sprint.
Under the hood
Fplll 5.0.0 switches from C++98 to C++11. While we haven’t upgraded all code to take advantage of C++11’s features, such as rvalue references, we try to make use of them when touching code. Marc Stevens helped a lot here by educating the rest of us. I, personally, also found Effective Modern C++ quite a good read.
Fplll now also has a test suite, testing basic arithmetic, LLL, BKZ, SVP, sieving and the pruner. Test coverage is not complete but this quite an improvement over the 4.x series. We run these tests on every pull request and commit to master.
Writing code using fplll as a library instead of a command line program used to be hit and miss: did the compiler instantiate that template? We now force instantiation of templates and link against fplll as a library ourselves during testing. We also added pkg-config support and improved the build system so that make -j8 actually runs faster than make.
Finally, we also provide API documentation online. You will notice that we adopted a naming convention inspired by PEP 8: ClassName.function_name.
LLL
In LLL land not much has changed in fplll 5.0.0, e.g. HPLLL wasn’t merged into fplll yet. However, Shi Bai added optional support for double-double (106 bits) and quad-double (212 bits) precision using the qd library. In our experience, double-double provides a speed-up, but quad-double does not.
Faster Enumeration
Marc contributed a new implementation of enumeration. This implementation is recursive but avoids the usual performance drawback of recursive enumeration by making the compiler untangle it during compile time. The new implementation is not as fast as it could be, but it is noticeable faster than what was in the 4.x series. In the process, we also made enumeration on different objects thread-safe by eliminating global variables.
BKZ 2.0
fplll 5.0 is the first public (open-source or not) complete implementation of BKZ 2.0 (see https://github.com/Tzumpi1/BKZ_2 for a previous but incomplete implementation). As mentioned in a previous post, the collection of techniques known as BKZ 2.0 is used in lattice-based cryptography to estimate the cost of strong lattice reduction. This lead to the somewhat strange situation where everybody was essentially relying on a table in the BKZ 2.0 paper to predict the cost of certain cryptanalytical attacks without being able to reproduce or verify these numbers.
BKZ 2.0’s biggest improvement is due to the use of extreme pruning (Section 4.1 of the BKZ 2.0 paper). This, first of all, entails computing optimal pruning coefficients. The implementation in fplll for computing these coefficients — the pruner — was contributed by Léo Ducas. He also wrote the first implementation in Python for using these parameters in BKZ, i.e. by adding re-randomisation. I then re-implemented that part in C++ for fplll (and in Python for fpylll).
BKZ 2.0 also uses recursive preprocessing with BKZ in a smaller block size (Section 4.2 of the BKZ 2.0 paper). The implementation in fplll was written by me back in 2014.
Around the same time, Joop van der Pol contributed using the Gaussian heuristic bound in enumeration (Section 4.3 of the BKZ 2.0 paper)
Fplll also ships with strategies for BKZ reduction up to block size 90. These strategies provide pruning parameters and block sizes for recursive preprocessing. These strategies were computed using the strategizer discussed below.
Self-Dual BKZ & Slide Reduction
Michael Walter contributed implementations of the Self-Dual BKZ algorithm and Slide Reduction. We don’t ship dedicated reduction strategies for these algorithms, but the default strategies should work reasonably well (I haven’t tried). Hence, these algorithms can now easily compared against each other and will all benefit from future improvements to fplll such as faster enumeration etc.
Python Interface
C++11 has made writing C++ a lot easier. Still, C++ might not be for everyone. Python, however, is for everyone. In particular, with Sage and SciPy, Python has become a central language for computational mathematics. To make it easy for researchers to try out new algorithmic ideas, tweak algorithms or simply to experiment with existing algorithms there is now fpylll which provides an interface to fplll’s API from Python and implements a few algorithms using that API in pure Python. see my previous post on fpylll for details.
Strategizer
The set of strategies shipped with fplll were computed using a Python library built on top of fpylll. This transparency allows others to reproduce and verify our choices or to improve them.
Sieving
Shi Bai also contributed implementations of the GaussSieve as well as the TupleSieve. However, these can at present not be used as SVP oracles inside BKZ-style algorithms.
Benchmarks
To get an impression of the difference between fplll 4.x and 5.x, consider the 
latticegen q 100 50 30 b -randseed 1337
In the table below, 

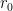
| software | |
strategy | time | |
|---|---|---|---|---|
| fplll 4.0.4 | 40 | – | 326.43s | 1.10e10 |
| fplll 5.0.0 | 40 | – | 75.71s | 1.22e10 |
| fplll 5.0.0 | 40 | default | 3.64s | 1.17e10 |
| fplll 5.0.0 | 60 | default | 120.67s | 8.85e9 |
Sage
Now that fplll 5.0.0 is out, we’ll work on integrating it into Sage (discussion and ticket).
