We – Alex Davidson, Amit Deo, Daniel Gardham and me – have updated our pre-print Crypto Dark Matter on the Torus: Oblivious PRFs from shallow PRFs and TFHE. It has been around for a while, but I am now somewhat confident that we won’t squeeze more performance out of it for the time being, so this feels like the right time to blog about.
What is an OPRF and why should I care? Oblivious pseudorandom functions allow two parties to compute a pseudorandom function (PRF) 



Sounds good, seems solved! Despite the wide use of (V)OPRFs, most constructions are based on classical assumptions, such as Diffie-Hellman (DH), RSA or even pairing-based assumptions. Indeed, DH-based OPRFs are currently being standardised by the IETF. Their vulnerability to quantum adversaries makes it desirable to find post-quantum solutions, however, known candidates are much less efficient.
Oblivious PRF and FHE, I see where this is going … Indeed, given fully homomorphic encryption (FHE), there is a natural (P)OPRF candidate. The client FHE encrypts input 

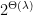
Yet, if we expand our circuit model to arithmetic circuits with both mod 


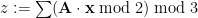
where arithmetic operations are over the integers and 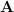
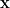
So what did you actually do? We construct a novel POPRF from lattice assumptions and the “Crypto Dark Matter” PRF candidate in the random oracle model. At a conceptual level, our scheme exploits the alignment of this family of PRF candidates, relying on mixed modulus computations, and programmable bootstrapping in the torus fully homomorphic encryption scheme (TFHE). This allows us to construct an OPRF candidate using only one level of bootstrapping (the most expensive operation in a FHE computation). We also explore a cut-and-choose based strategy for adding verifiability to our OPRF.
Performance. For the core online OPRF functionality, we require amortised 10.0KB communication per evaluation and a one-time per-client setup communication of 2.5MB. I’d say his makes our OPRF practical size-wise. Client computation costs are also somewhat manageable but server computation costs are quite unattractive unless you’re willing to invest in some FHE co-processor. We have some early benchmarks (using tfhe-rs) running the server code in ~150ms on 64 cores. Let me stress that this does not account for “circuit privacy” which should add a factor of 5x to 10x (or the zk systems we need, but we assume those won’t add that much overhead in computation, we do include their sizes in the estimates above). Moreover, our relatively small sizes are the effect of aggressive packing, unpacked the key material should weight about ~2GB in RAM.
Implementation. We do have a somewhat complete implementation of our scheme, but it is in SageMath and thus extremely slow. I should mention, though, that this implementation, too, does not cover the zero-knowledge proof systems we rely on to achieve malicious security.
