Our paper “Faster Enumeration-based Lattice Reduction: Root Hermite Factor 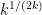

We give a lattice reduction algorithm that achieves root Hermite factor
and polynomial memory. This improves on the previously best known enumeration-based algorithms which achieve the same quality, but in time
. A cost of
Concretely, this work reduces the cost of enumeration-based, i.e. polynomial memory, BKZ-k in dimension 


In the plot below “Alg. 3” is our new algorithm (well, our “practical variant”), “Fig. 2” refers to the 

Speaking of lower bounds, if we assume free preprocessing then we can go even below the leading constant of 

The key idea behind our algorithm is that enumerating over a typical HKZ shape (red-ish part in the plot below) has cost 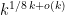

Thus, we need to make sure enumeration sees something more like the green-ish shape rather than the red-ish shape. To make that happen in (SD)BKZ, we preprocess a larger block than we enumerate over to push the “not so nice” part out of the enumeration window (FWIW I pitched the name “procrastinating BKZ” for that to my coauthors but they weren’t convinced):
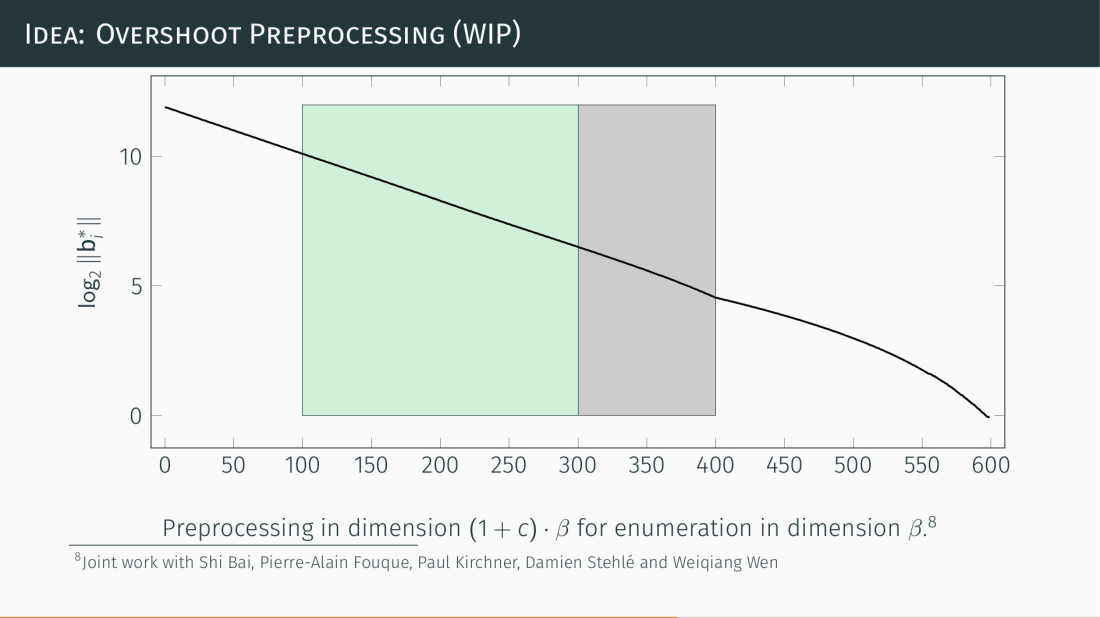
Btw. the two slides above are from my talk at the Simon’s Institute where I explained (amongst other things) the key idea behind our algorithm.
Now, to explain how we can beat 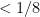
PS: The ePrint paper not only contains all the raw data in our plots as an attachment but also the FPyLLL-based source code of our simulations and implementations.
