This week our reading group studied Homomorphic Encryption from Learning with Errors: Conceptually-Simpler, Asymptotically-Faster, Attribute-Based by Craig Gentry, Amit Sahai and Brent Waters: a 3rd generation fully homomorphic encryption scheme.
The paper is partly motivated by that multiplication in previous schemes was complicated or at least not natural. Let’s take the BGV scheme where ciphertexts are simply LWE samples 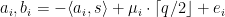
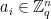




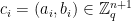

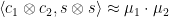
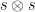

However, this is only unnatural in this particular representation. To see this, let’s rewrite 
![f_i = b_i - \sum_{j=1}^n a_{ij} \cdot x_j \in \mathbb{Z}_q[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=f_i+%3D+b_i+-+%5Csum_%7Bj%3D1%7D%5En+a_%7Bij%7D+%5Ccdot+x_j+%5Cin+%5Cmathbb%7BZ%7D_q%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=ffffff&fg=000000&s=0&c=20201002)


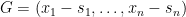
Now, multiplying 



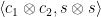
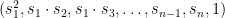


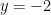
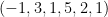



Still, 
Let’s look at what happens when we reduce 
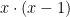
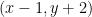



Of course, this process, as just described, assumes access to 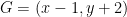
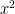
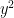


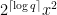




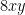
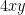

The Scheme
Ciphertexts in the GSW13 scheme are 








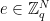

Ciphertexts in fully homomorphic encryption schemes are meant to be added and multiplied. Starting with addition, consider 

Moving on to multiplication, we first observe that if matrices 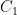
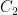

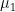


Considering 

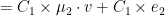

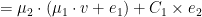

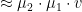
In the above expression 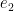
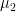
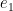
Multiplicative Depth
Assume 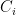




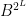
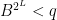

To improve on this, we need a new notion. We call 
In what follows, we will only consider a NAND gate: 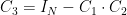
NAND is a universal gate, so we can build any circuit with it. However, in this context its main appeal is that it ensures that the messages 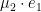
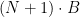

Flatten
We’ll make use of an operation BitDecomp which splits a vector of integers 



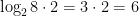
def bit_decomp(v): R = v.base_ring() k = ZZ((R.order()-1).nbits()) w = vector(R, len(v)*k) for i in range(len(v)): for j in range(k): if 2**j & ZZ(v[i]): w[k*i+j] = 1 else: w[k*i+j] = 0 return w
We also need a function which reverses the process, i.e. adds up the appropriate powers of two: 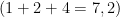

BitComp.
def bit_comp(v): R = v.base_ring() k = ZZ((R.order()-1).nbits()) assert(k.divides(len(v))) w = vector(R, len(v)//k) for i in range(len(v)//k): for j in range(k): w[i] += 2**j * ZZ(v[k*i+j]) return w
Actually, the definition of BitComp is a bit more general than just adding up bits. As defined above — following the GSW13 paper — it will add up any integer entry of Flatten which we define as BitDecomp(BitComp(⋅)).
flatten = lambda v: bit_decomp(bit_comp(v))
Finally we also define PowersOf2 which produces a new vector from 
def powers_of_two(v): R = v.base_ring() k = ZZ((R.order()-1).nbits()) w = vector(R, len(v)*k) for i in range(len(v)): for j in range(k): w[k*i+j] = 2**j * v[i] return w
For example the output of PowersOf2 on 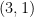
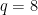


which can verified by recalling integer multiplication. For example, 

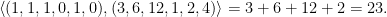
Or in the form of some Sage code:
q = 8 R = IntegerModRing(q) v = random_vector(R, 10) w = random_vector(R, 10) v.dot_product(w) == bit_decomp(v).dot_product(powers_of_two(w))
Furthermore, let 



because 
Finally, we have

by combining the previous two statements.
For example, let 

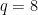
BitComponBitDecompongives
,
- For the left-hand side we have
.
- For the right-hand side we hve
.

The same example in Sage:
q = 8 R = IntegerModRing(q) a = vector(R, (2,3,0)) b = vector(R, (3,)) bit_comp(a).dot_product(b) == flatten(a).dot_product(powers_of_two(b))
Hence, running Flatten on 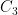
Key Generation
It remains to sample a key and to argue why this construction is secure if LWE is secure for the choice of parameters.
To generate a public key, pick LWE parameters 


The secret key is 




To encrypt, sample an 


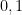
BitDecomp on the output to get a

For correctness, observe:
+ something small.


The security argument is surprisingly simple. Consider 
Flatten it reveals nothing more than 
Unpacking 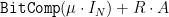

You promised 3rd Generation
So far, this scheme is not more efficient than previous ring-based schemes such as BGV, even asymptotically. However, an observation by Zvika Brakerski and Vinod Vaikuntanathan in Lattice-Based FHE as Secure as PKE changed this. This observation is that the order of multiplications matters. Let’s multiply four ciphertexts 
The traditional approach would be:
,

In this approach the noise grows as follows:



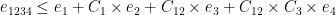

Note the 
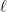

In contrast, consider this sequential approach:
,
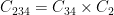
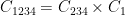
Under this order, the noise grows as:

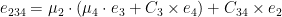
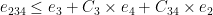

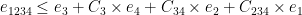
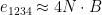
Note that each 
Footnotes:
I suggest people start writing Boom instead of qed.

Hello Martin,
thank you for this great article. Do all lattice-based cryptosystems support homomorphic? I know that there exists fully, somewhat and partially and they all support homomorphic addition, but I’m not sure whether that can be said about all lattice-based cryptosystems.
Also how large can these potential numbers to be encrypted and operations performed on really get, in terms of practicality?
Take care
Alex