Recently, Yupu Hu and Huiwen Jia put a paper on the Cryptology ePrint Archive which describes a successful attack of the GGH (and GGHLite) candidate multilinear map. The attack does not try to recover the secret 

For GGHLite the Ext-GCDH problem is defined as computing the higher order bits of 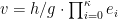

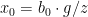


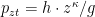
All elements involving a 
![R_q = \mathbb{Z}_q[x]/(x^n+1)](https://s0.wp.com/latex.php?latex=R_q+%3D+%5Cmathbb%7BZ%7D_q%5Bx%5D%2F%28x%5En%2B1%29&bg=ffffff&fg=000000&s=0&c=20201002)

![R = \mathbb{Z}[x]/(x^n+1)](https://s0.wp.com/latex.php?latex=R+%3D+%5Cmathbb%7BZ%7D%5Bx%5D%2F%28x%5En%2B1%29&bg=ffffff&fg=000000&s=0&c=20201002)

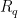





In a non-interactive key exchange (NIKE) based on GGH-like maps, the higher order bits of the value 
class NIKESloppy:
"""
A sloppy implementation of NIKE for testing.
By "sloppy" we mean that we do not care about distributions,
verifying some properties or exact sizes.
"""
def __init__(self, n, kappa):
"""
Initialise a new sloppy GGHLite instance.
:param n: dimension (must be power of two)
:param kappa: multilinearity level `κ`
"""
self.n = ZZ(n)
if not n.is_power_of(2):
raise ValueError
self.kappa = ZZ(kappa)
self.R = ZZ["x"]
self.K = CyclotomicField(2*n, "x")
self.f = self.R.gen()**self.n + 1
self.sigma = self.n
self.sigma_p = round(self.n**(ZZ(5)/2) * self.sigma)
self.sigma_s = round(self.n**(ZZ(3)/2) * self.sigma_p**2)
self.q = next_prime((3*self.n**(ZZ(3)/2) * self.sigma_s*self.sigma_p)**(3*self.kappa))
self.Rq = self.R.change_ring(IntegerModRing(self.q))
g = self.discrete_gaussian(self.sigma)
# we enforce primality to ensure we can invert mod ⟨g⟩
while not self.K(g).is_prime():
g = self.discrete_gaussian(self.sigma)
h = self.discrete_gaussian(sqrt(self.q))
z = self.Rq.random_element(degree=n-1)
# encoding of one
a = self.discrete_gaussian(self.sigma_p/self.sigma)
self.y = ((1+a*g) * z.inverse_mod(self.f)) % self.f
# encoding of zero
b0 = self.discrete_gaussian(self.sigma_p/self.sigma)
self.x0 = ((b0*g) * z.inverse_mod(self.f)) % self.f
# encoding or zero
b1 = self.discrete_gaussian(self.sigma_p/self.sigma)
self.x1 = ((b1*g) * z.inverse_mod(self.f)) % self.f
# zero testing parameter
self.pzt = h*z**kappa * self.Rq(g).inverse_mod(self.f)
# we migh as well give these to the attacker, as they can be computed
# easily
self.G = self.canonical_basis(g)
self.I = self.K.ideal([self.R(row.list()) for row in self.G.rows()])
Logarithms of Euclidean norms are useful as “small” and “not-so-small” are what distinguishes between secret and not-so-secret.
@staticmethod
def norm(f):
"Return log of Euclidean norm of `f`"
return log(max(map(abs, f)), 2.).n()
It is easy to compute a canonical basis for 
def canonical_basis(self, g):
"Return HNF of g"
x = self.R.gen()
n = self.n
G = [x**n + ((x**i * g) % self.f) for i in range(n)]
G = [r.list()[:-1] for r in G]
G = matrix(ZZ, n, n, G)
return G.hermite_form()
It will be useful below to compute short remainders modulo some number ring element. We use Babai’s rounding trick for that.
def rem(self, h, g):
"""
Compute a small remainder of `h` modulo `g`
:param h: a polynomial in ZZ[x]/x^n+1
:param g: a polynomial in ZZ[x]/x^n+1
:returns: small representative of `h mod g`
"""
g_inv = g.change_ring(QQ).inverse_mod(self.f)
q = (h * g_inv) % self.f
q = self.R([round(c) for c in q.coefficients()])
r = (h - q*g) % self.f
return r
We do not care about distributions of elements in our toy example, so we simply return random polynomials where the coefficients are bounded by 
def discrete_gaussian(self, sigma):
"""
sample element with coefficients bounded by sigma
.. note:: this is obviously *not* a discrete Gaussian, but we don't care here.
"""
sigma = round(sigma)
return self.R.random_element(x=-sigma, y=sigma, degree=self.n-1)
We need a function to sample new encodings:
def sample(self):
"""
Sample level-0 and level-1 encodeing.
"""
e0 = self.discrete_gaussian(self.sigma_p)
r0 = self.discrete_gaussian(self.sigma_s)
r1 = self.discrete_gaussian(self.sigma_s)
u0 = ((e0*self.y + r0*self.x0 + r1*self.x1)) % self.f
return e0, u0
For the final step we need to extract a representation over the Integers from our representation modulo 
![[-\lfloor q/2 \rfloor,\dots, \lfloor q/2 \rfloor]](https://s0.wp.com/latex.php?latex=%5B-%5Clfloor+q%2F2+%5Crfloor%2C%5Cdots%2C+%5Clfloor+q%2F2+%5Crfloor%5D&bg=ffffff&fg=000000&s=0&c=20201002)
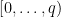
def extract(self, p, mul_pzt=True, drop_noise=True):
"""
Convert mod q element to element over the integers
:param p: a polynomial in ZZ[x]/x^n+1
:param mul_pzt: multiply by pzt
:param drop_noise: remove lower order terms
"""
p = p % self.f
if mul_pzt:
p = (self.pzt*p) % self.f
q = parent(p).base_ring().order()
f = []
for c in p.change_ring(ZZ).list():
if c<q/2:
f.append(c)
else:
f.append(c-q)
if drop_noise:
f = [f[i] >> floor(log(self.q//2, 2)) for i in range(self.n)]
return ZZ['x'](f)
Finally, we implement NIKE: we multiply 
def __call__(self, e0, U):
"""
Run NIKE with `e_0` and `U`
:param e0: a level-0 encoding
:param U: κ level-1 encodings
"""
if len(U) != self.kappa:
raise ValueError
t = prod(U) % self.f
t = t * e0 % self.f
t = self.extract(t)
return tuple(t.list())
Let me stress once more that the above is not a proper implementation of a GGH-like candidate multilinear maps. For starters, the method called discrete_gaussian does not return elements following a discrete Gaussian distribution. We also skipped several tests from the GGH and GGHLite specifications. However, this simplified variant is sufficient to explain the attack of Hu and Jia.
The attack proceeds in two steps. The first step was already known as the “weak discrete log attack”. (Update: Hu and Jia do not present the first step of their attack this way. Instead, they give another way of computing a “kind of” level-0 encoding from a, say, level-1 encoding. Damien Stéhle was the first to point out to me that this step can be replaced by the “normal” weak discrete log attack.) Say, we have some level-


for some 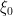


Similarly, we can compute:
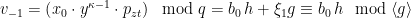
Now, assume 



def weak_dlog(params, u):
"""
Weak discrete log attack from [EC:GarGenHal13]_
:param params: GGH parameters
:param u: a level-1 encoding
"""
kappa = params.kappa
v0 = params.extract(u*params.x0*params.y**(kappa-2), drop_noise=False)
vn = params.extract(params.y**(kappa-1)*params.x0, drop_noise=False)
v0 = params.K(v0).mod(params.I)
vn = params.K(vn).mod(params.I)
r = (v0 * vn.inverse_mod(params.I)).mod(params.I)
return r.polynomial().change_ring(ZZ)
Now, compute representivatives 
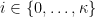
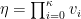


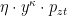
This is where Hu and Jia come in with a clever and remarkably simple step two. They define:

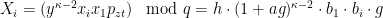
Again, note that the right hand sides have no modular reductions modulo
Recall that 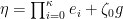
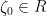
. Note that
is a multiple of
.
which holds because
is a multiple of
. Note that
has roughly the same size as
This effectively replaces the factor
in
. Consequently, we have
where the second summand is small. In other words, we have computed
i.e. we have solved the Ext-GCDH problem.


Here’s some Sage code implementing these three steps:
def ggh_break(params, U):
"""
Attack from [EPRINT:HuJia15]_
:param params: GGH parameters
:param U: κ+1 level-1 encodings
"""
if len(U) != params.kappa + 1:
raise ValueError
kappa = params.kappa
# large "level-0" encodings of U
V = [weak_dlog(params, u) for u in U]
# large "level-0" encoding of prod(U)
eta = prod(V) % params.f
# Y = (b_0 ⋅ h ⋅ (1+ag))^(κ-2) ⋅ (1+ag)
Y = params.extract(params.y**(kappa-1) * params.x0, drop_noise=False)
# X = (b_0 ⋅ h ⋅ (1+ag))^(κ-2) ⋅ (b_0⋅g)
X = params.extract(params.y**(kappa-2) * params.x0**2, drop_noise=False)
# η'' = (Y ∏ u_i) mod X
eta_ = (eta * Y) % params.f
eta__ = params.rem(eta_, X)
# η''' = η'' ⋅ y/x
xy = params.y * params.x0.inverse_mod(params.f) % params.f
eta___ = params.extract(xy * eta__, mul_pzt=False)
return tuple(eta___.list())
Finally, let’s put everything together and run the attack. If everything is well, then the following code should print the same tuple three times.
def run(n, kappa):
params = NIKESloppy(n, kappa)
EU = [params.sample() for i in range(kappa+1)]
E = [eu[0] for eu in EU]
U = [eu[1] for eu in EU]
# fist make sure NIKE is correct, by running it twice
print params(E[0], U[1:])
print params(E[-1], U[:-1])
# now run the attack
print ggh_break(params, U)

Reblogged this on Pathological Handwaving.