When a year ends people make lists. I can only guess that several people are currently busy with writing “The 5 most revised papers on eprint ” and “The 8 best IACR flagship conference rump session presentations of 2014”. Since all the good lists are taken, my list has to be a little bit more personal. Alas, here is my list of stuff that happened in open-source computational mathematics in 2014 around me. That is, below I list what developments happened in 2014 and try to provide an outlook for 2015 (so that I can come back in a year to notice that nothing played out as planned).
If you are interested in any of the projects below feel invited to get involved. Also, if you are student and you are interested in working on one of the (bigger) projects listed below over the summer, get in touch: we could try to turn it into a Google Summer of Code 2015 project.
fplll: lattice reduction
This year I mainly worked on lattice-based cryptography. At the heart of this line of research is the assumption that finding short vectors in discrete subgroups of 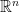
The first algorithm for lattice reduction was the LLL algorithm which proved to be incredibly useful for many applications in cryptography and beyond. LLL is implemented in NTL, Pari, fplll and – as of this summer – in FLINT 2; fplll typically seems to be the fastest implementation (cf. the link above for a comparison with FLINT 2).
While LLL runs in polynomial time (read: fast) it only gives a “short vector” which is about 
To produce shorter vectors we typically employ the BKZ algorithm which is parameterised by a block size. The larger the block size the better the output but the longer it takes. BKZ is implemented in NTL and fplll, typically fplll is faster.
At AsiaCrypt 2011 Chen and Nguyen presented their results of combining various known techniques for speeding up the BKZ algorithm. They call the result BKZ 2.0. They also applied BKZ 2.0 to various benchmark problems and claimed substantial improvements over the public state of the art. However, for some reasons only known to the authors and the AsiaCrypt 2011 programme committee, their paper was accepted without them publishing their source code. Since then we’re in the somewhat strange situation that everybody believes BKZ can be made to run much faster (you might even get your paper rejected because you are not using the state of the art, i.e. BKZ 2.0) but no one has publicly reproduced these results.
In autumn we took some first steps towards fixing this situation by adding better pre-processing and an easier linear pruning interface to fplll. I know that others have patched fplll as well, but as far as I know they never made their changes public. In the process, we also moved fplll’s development to Github, so send your pull requests.
While the result is an improvement over plain BKZ, there’s still a lot of work to be done to come even close to the results of Chen and Nguyen. For example, they use extreme pruning instead of the simple linear pruning strategy currently implemented in fplll and it’s not clear how to pick pruning parameters for extreme pruning … however, there’s a paper on the arXiv which promises an answer to this question. Furthermore, currently the user has to pick pre-processing parameters by hand, something the implementation should take care off by default. Finally, a recent paper on ePrint claims that phase-based enumeration is much faster than the Kannan-Helfrich enumeration algorithm which is implemented everywhere including fplll. I’d consider addressing any of these issues a valuable contribution.
dgs: sampling from a discrete Gaussian distribution
A central step in most lattice-based cryptography is to sample from a discrete Gaussian. A discrete Gaussian distribution over the Integers is a distribution where the integer x is sampled with probability proportional to 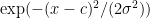
C library available that allows to sample from a discrete Gaussian with reasonable efficiency. Now there is. The library is called dgs and it is included in Sage by default and also unpins our GGHLite implementation, so it has seen some usage.
A few things still need to be done, though. Some bugs were fixed in the stand-alone library but not ported back to Sage, yet. Also, the library would benefit from more tests being run by make check. Finally, implementing the Discrete Ziggurat algorithm would complete the picture.
oz: computing in some Cyclotomic number rings
Most of the interesting code in our GGHLite implementation is in the oz submodule which implements arithmetic in ![\mathbb{Z}[x]/(x^n+1)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5Bx%5D%2F%28x%5En%2B1%29&bg=ffffff&fg=000000&s=0&c=20201002)
When we are doing this, we should probably also split up the dgsl module. This module implements sampling from a discrete Gaussian distribution over arbitrary lattices (in contrast to dgs which implements it over the integers). This module contains two essentially independent parts. One part samples from lattices represented by a basis matrix using the GPV algorithm. Another part samples from ideal lattices represented by an ideal generator in
Linear algebra over small finite fields
I didn’t work as much on linear algebra over small finite fields as I would have liked to in 2014. I doubt I’ll make it a priority of mine in 2015 either, so if anybody wants to jump in to help, that’d be much appreciated.
M4RI
M4RI implements dense linear algebra over 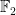
If you read this blog, you probably know that Enrico’s implementation of Gaussian elimination is faster than our own. As far as I can tell the advantage of GF2Toolkit over M4RI comes from avoiding a lot of management overhead. To illustrate this point, consider the following output of Google’s perf tools on running M4RI’s Gaussian elimination on a 4096 x 4096 dense full rank matrix:
. . 1121: switch(__M4RI_M4RM_NTABLES) {
42 131 1122: case 8: t[7] = T[ 7]->rows[ L[7][ (a >> 7*k) & bm ] ];
57 79 1123: case 7: t[6] = T[ 6]->rows[ L[6][ (a >> 6*k) & bm ] ];
27 47 1124: case 6: t[5] = T[ 5]->rows[ L[5][ (a >> 5*k) & bm ] ];
14 25 1125: case 5: t[4] = T[ 4]->rows[ L[4][ (a >> 4*k) & bm ] ];
29 52 1126: case 4: t[3] = T[ 3]->rows[ L[3][ (a >> 3*k) & bm ] ];
15 34 1127: case 3: t[2] = T[ 2]->rows[ L[2][ (a >> 2*k) & bm ] ];
14 27 1128: case 2: t[1] = T[ 1]->rows[ L[1][ (a >> 1*k) & bm ] ];
6 17 1129: case 1: t[0] = T[ 0]->rows[ L[0][ (a >> 0*k) & bm ] ];
. . 1130: break;
. . 1131: default:
<snip>
. . 1137: switch(__M4RI_M4RM_NTABLES) {
970 1946 1138: case 8: _mzd_combine_8(c, t, wide); break;
The numbers in the first two columns indicate how much time we spent in each line. As you can see, we’re spending between 20% and 25% of the time it takes to perform additions (_mzd_combine_8) with setting them up (everything else); We are performing 4096/128 · 8 = 256 XORs in _mzd_combine_8, which isn’t much and so our setup overhead is hurting us.
M4RIE
M4RIE is a library for fast arithmetic with matrices over small even characteristic fields, i.e. ![\mathbb{F}_2[x]/f(x)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_2%5Bx%5D%2Ff%28x%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbb{F}_2[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_2%5Bx%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Last year I added some code to M4RIE for computing with matrices over
Another area for improvement is that the formulas we use to realise multiplication for degrees up to 16 are not always optional. In particular, we know that the following improvements are possible for degree 6 (18 → 15), degree 8 (27 → 24), degree 9 (31 → 30), degree 10 (36 → 33), degree 11 (40 → 39), degree 12 (45 → 42), degree 13 (49 → 38), degree 14 (55 → 51), degree 15 (60 → 54), degree 16 (64 → 60), where the numbers in brackets are the current and the best known number of multiplications over
CryptoMiniSAT
CryptoMiniSAT is the SAT solver with the best integration into Sage. However, Sage is still using CryptoMiniSAT 2.9.6 instead the more recent 4.x series. This is partly because we can’t get our act together and partly because Máté decided to go with CMake instead of Autotools in the current CryptoMiniSat series. There’s a pull request idling around which improves Autotools support for CryptoMiniSAT. I should probably follow up on this. Once this is taken care of (which shouldn’t take more than 1-2 hours), we should update CryptoMiniSAT in Sage. The interface of CryptoMiniSAT hasn’t changed much, so this second step shouldn’t be too hard either. Some options might have changed, so I would guess solverconf_helper.cpp would need to be adapted slightly.
Sage
Sage saw four major releases in 2014. Sage 6.1 in February, Sage 6.2 in May, Sage 6.3 in August and Sage 6.4 in November.
My main contributions this year were to add better support for computing with lattices: I mainly worked on the fplll interface (see above) and on sampling from discrete Gaussian distributions (also above). I also fixed the occational bug and reviewed the occational ticket, but not as much as I would have liked to. In fact, there’s just been a friendly reminder that we have way too many tickets for Sage with status “needs review” which means that someone contributed some code and that code is now waiting to be reviewed so it can be included (or revised).
As always there’s much to be done for Sage, but too little time. Here are some examples.
SAT Solvers
Besides the tasks listed under the CryptoMiniSAT heading, more work should be done on Sage’s SAT solving capabilities. Currently, Sage will fail to solve any SAT problem without installing additional software because it believes that no SAT solver is included by default. Turns out, this is not correct. That is, Sage ships with GLPK and GLPK can be used as a SAT solver. That won’t break any performance records but it’s better than nothing. So we should use GLPK as the poor person’s SAT Solver. Indeed, adding support for this should be fairly straight forward. Here’s what Nathann Cohen had to say who pointed me towards GLPK:
There are some sentences about it at the end of that : http://en.wikibooks.org/wiki/GLPK/Mixing_GLPK_with_other_solver_packages
And this page says that there is a dedicated pdf in GLPK’s doc: http://en.wikibooks.org/wiki/GLPK/Literature#Official_GLPK_documentation
…
But it seems that the interface is pretty basic, and may have to work through files… or though LP ! But as you can already produce DIMACS SAT instances with you code, perhaps you can just call GLPK on that? It would be better than nothing, plus you can say that the feature is standard, and also write everywhere that users can download a “real solver” if they want to.
Secondly, while Sage currently is happy to write DIMACS files (the standard format for SAT problems) it does not read DIMACS files.
FGB
For a while now I’ve had adding an interface to FGB on my TODO list. FGB is Jean-Charles Faugère’s implementation of the F4 Gröbner basis algorithm. It is not open source, but it is a good implementation of F4, something which isn’t exactly widely available in the open-source world. Besides, being able to easily compare with FGB surely would be useful.
SCIP
When I worked on solving multivariate systems of equations with noise I added support for the SCIP constraint integer programming solver to Sage. Constrained integer programming allows to solve non-linear systems of equations and inequalities. For example, it allows to model and solve systems which contain constrains like 


This Python library has a PicoSAT extension, and a DIMACS parser:
https://github.com/cjdrake/pyeda
Reblogged this on Arcanus's Random Stuffs.