I’m rather excited to report that EPSRC decided to fund our grant titled “Social Foundations of Cryptography”. Our project tries to do two things.
First, we want to ground cryptographic security notions in rigorous social science findings rather than “simply” our intuitions that we write down in the introductions of our papers. In Burdens of Proof, Jean-François Blanchette characterises what we – as cryptographers – do as follows:
New cryptographic objects are generated through more or less straightforward combinations of elements of the cryptographic toolbox, such as threshold, proxy, or fairness properties. Like so many modular Lego pieces, cryptographic primitives and design patterns are assembled in new schemes and protocols exhibiting security properties with no obvious real-world equivalents. This creative process is one of the core professional activities of cryptographers, rewarded through conference presentations, journal publications, and commercial patents. Yet the cryptographic paper genre seems to require that these products of mathematical creativity be justified in some “real-world” setting, motivated either by their potential application, their evidential value, or the new threats they identify. These justificatory scenarios are remarkable in their assumptions that the properties of cryptographic objects, as designed and discussed by cryptographers, will translate transparently into the complex social settings they describe.
Our approach is to flip this approach around: make cryptographic security notions contingent on ethnographic findings. This is, of course, a tall order when it comes to, say, PRP security of a block cipher (I enjoy Phil Rogaway’s discussion of cryptographic definitions, Phil is also on our advisory board), but it is perhaps a bit more obvious when we talk about ideal functionalities in simulation-based proofs of complex cryptographic protocols. For these ideal functionalities it is not at all immediately clear they are indeed “ideal”. Still, this remains quite a daunting project and I’m rather nervous about it.
Second, we picked the settings of large-scale urban protests, i.e. ask about security notions and needs of protesters confronting agents of the state. We think these settings (we plan on doing field work in different sites internationally) are rich yet specific. That is, notions of security depend on context and grounding cryptographic notions in such contexts can unlock insights. Post-compromise security needs for a business traveller (having their phone confiscated at an airport) and for protesters (who face arrest) may be quite different.
Another key, distinguishing, feature of these settings is that security notions are quite collective rather than individual, according to our pilot study. In this study we interviewed protesters involved in the Anti Extradition Bill protests in Hong Kong (2019/2020). This work then motivated us to then take a deeper look at Telegram. However, this pilot study has the big caveat that its inquiry was somewhat limited, by necessity.
Our study was an interview study, meaning participants self-selected to discuss their security needs with us. Yet, a key challenge in engaging those who depend on security technology is that they are not trained information security professionals. They do not know and, indeed, should not need to know, for example, that confidentiality requires integrity, that existing onboarding practices can be phrased in the language of information security, which different security notions cannot be achieved simultaneously and what guarantees, say, cryptography, can give if asked. Therefore, to know exactly what is taken for granted, or put otherwise, expected or desired, in social interactions, social and technical protocols and, indeed, cryptography is of critical import.
This is where ethnography comes in, as it is uniquely placed to “unearth what the group (under study) takes for granted”. In a nutshell, it’s a social science method involving prolonged field work, i.e. staying with the group under study, to observe not only what they say but also what their social reality and practice is.
On the cryptographic side, our project consists of Ben Dowling (Sheffield) and me. On the ethnography side, it’s Andrea Medrado (Westminster) and Rikke Jensen (RHUL). But we’re hiring! We will have one postdoc position in ethnography at RHUL (perhaps not so relevant to the audience of this blog, see Rikke’s blog post) and one postdoc position in cryptography. This position is only scheduled to start in a year, but if you’re interested please let us know, we have some flexibility about when to put it on the market.
I’ve hired for postdoc positions before, but I think I’ve never been this nervous about that process as here. If working on the protest setting and putting what you’ll do at the mercy of ethnographic findings is for you, please reach out!
Our project website is here: https://social-foundations-of-cryptography.gitlab.io/
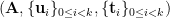 s.t.
s.t.  , with
, with  short, it is hard to find a short
short, it is hard to find a short 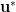 s.t.
s.t.  .
.  -PRISIS is hard
-PRISIS is hard , as was shown in
, as was shown in  together: a server supplying a key
together: a server supplying a key  and a user supplying a private input
and a user supplying a private input  . The server does not learn
. The server does not learn  and the user does not learn
and the user does not learn  . The server then evaluates the PRF homomorphically or “blindly” using a key derived from
. The server then evaluates the PRF homomorphically or “blindly” using a key derived from  to obtain a PRF resisting attacks with complexity
to obtain a PRF resisting attacks with complexity 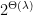 .
.  and mod
and mod  gates for
gates for  both primes, shallow proposals
both primes, shallow proposals 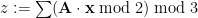
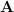 is the secret key. That’s it! The same work also contains a proposal to “upgrade” this weak PRF, defined for uniformly random inputs
is the secret key. That’s it! The same work also contains a proposal to “upgrade” this weak PRF, defined for uniformly random inputs 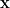 , to a full PRF, taking any
, to a full PRF, taking any 
 with domain
with domain ![[2^n]](https://s0.wp.com/latex.php?latex=%5B2%5En%5D&bg=ffffff&fg=000000&s=0&c=20201002) and codomain
and codomain ![[2^m]](https://s0.wp.com/latex.php?latex=%5B2%5Em%5D&bg=ffffff&fg=000000&s=0&c=20201002) , with
, with 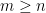 , a collision of
, a collision of  , and matching algorithms are known for any value of
, and matching algorithms are known for any value of  . The situation becomes different when one is looking for multiple collision pairs. Here, for
. The situation becomes different when one is looking for multiple collision pairs. Here, for 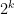 collisions, a query lower bound of
collisions, a query lower bound of  was shown by Liu and Zhandry (EUROCRYPT 2019). A matching algorithm is known, but only for relatively small values of
was shown by Liu and Zhandry (EUROCRYPT 2019). A matching algorithm is known, but only for relatively small values of  instead of the previous
instead of the previous 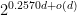 .
. 