Sage 5.10 was released earlier today. It has the following goodies I particularly care about:
Faster Dense Linear Algebra over GF(2)
TL;DR: We updated M4RI to the most recent upstream release which is better suited for modern CPUs.
After Enrico Bertolazzi and Anna Rimoldi kicked out butts with their pre-print we went to work to re-tune M4RI. That is, I don’t agree with their premise that their new algorithm is the (main) cause of their impressive performance. As a result M4RI got considerably faster on modern CPUs.
Here’s a comparison of Sage 5.8 (which has the same performance characteristics as 5.9 for this stuff) and Sage 5.10. Sage 5.8 goes first:
sage: A = random_matrix(GF(2),2^14, 2^14)
sage: B = random_matrix(GF(2),2^14, 2^14)
sage: %time A*B
CPU times: user 4.46 s, sys: 0.02 s, total: 4.48 s
Wall time: 4.50 s
sage: %time A.echelonize()
CPU times: user 2.53 s, sys: 0.00 s, total: 2.53 s
Wall time: 2.54 s
Now Sage 5.10 which is 1.22 times faster for multiplication and 1.17 times faster for elimination in this particular benchmark.
sage: A = random_matrix(GF(2),2^14, 2^14)
sage: B = random_matrix(GF(2),2^14, 2^14)
sage: %time A*B
CPU times: user 3.61 s, sys: 0.04 s, total: 3.65 s
Wall time: 3.66 s
sage: %time A.echelonize()
CPU times: user 2.16 s, sys: 0.00 s, total: 2.17 s
Wall time: 2.17 s
For comparision, Magma 2.15-10 takes 4.5 seconds for this multiplication and Magma 2.18-7 takes 5 seconds on the same machine. See here for details on the M4RI update.
Faster Dense Linear Algebra over GF(2^e)
TL;DR: Improvements over GF(2) have a knock-on effect on GF(2^e) and we upgraded M4RIE to the newest upstream release which extends the supported degree size up to 
M4RIE recently dropped its dependency on Givaro and extended the degrees it supports up to 16. Sage 5.10 updates to this new release and extends the finite field size that is covered by M4RIE to 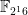 . This means a huge performance improvements for dense linear algebra over
. This means a huge performance improvements for dense linear algebra over 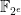 for
for  . Note, however, that these cases are not fully optimised yet, so that it’s not the fastest implementation – in this range – yet. Sage 5.8 first:
. Note, however, that these cases are not fully optimised yet, so that it’s not the fastest implementation – in this range – yet. Sage 5.8 first:
sage: A = random_matrix(GF(2^8,'a'),10^4, 10^4)
sage: B = random_matrix(GF(2^8,'a'),10^4, 10^4)
sage: %time A*B
CPU times: user 32.07 s, sys: 0.48 s, total: 32.56 s
Wall time: 32.67 s
10000 x 10000 dense matrix over Finite Field in a of size 2^8
sage: A = random_matrix(GF(2^12,'a'),10^3, 10^3)
sage: B = random_matrix(GF(2^12,'a'),10^3, 10^3)
sage: %time A*B # Sage 5.8 uses generic Python code to do this
CPU times: user 339.02 s, sys: 0.70 s, total: 339.72 s
Wall time: 340.86 s
1000 x 1000 dense matrix over Finite Field in a of size 2^12
Now, Sage 5.10 which is 1.16 times and 1420 times faster respectively for these benchmarks.
sage: A = random_matrix(GF(2^8,'a'),10^4, 10^4)
sage: B = random_matrix(GF(2^8,'a'),10^4, 10^4)
sage: %time A*B # knock-on effect from GF(2) improvements
CPU times: user 27.42 s, sys: 0.62 s, total: 28.04 s
Wall time: 28.14 s
10000 x 10000 dense matrix over Finite Field in a of size 2^8
sage: A = random_matrix(GF(2^12,'a'),10^3, 10^3)
sage: B = random_matrix(GF(2^12,'a'),10^3, 10^3)
sage: %time A*B # new code in M4RIE
CPU times: user 0.23 s, sys: 0.01 s, total: 0.24 s
Wall time: 0.24 s
1000 x 1000 dense matrix over Finite Field in a of size 2^12
For comparison, Magma 2.15-10 takes 3.79 seconds and Magam 2.18-7 takes 0.16 seconds for the latter benchmark. This highlights that M4RIE isn’t what it should be yet in that range (see here for details).
A Learning With Errors Instance Generator
I’ve written about it here.
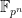 . We spend some time on this in Warwick and developed this idea further (adding fun stuff like Mixed Integer Programming in the process) but did not get around to do much on this project in the mean time (I have explained the idea at the end of my
. We spend some time on this in Warwick and developed this idea further (adding fun stuff like Mixed Integer Programming in the process) but did not get around to do much on this project in the mean time (I have explained the idea at the end of my 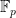 it takes to do a multiplication in
it takes to do a multiplication in  . In theory these plots should all have slope 0.
. In theory these plots should all have slope 0.


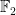 , we need the ability to create finite extensions of
, we need the ability to create finite extensions of 